Kategorie: Informationstechnologie
-

Reha: Mein Weg zurück mit neuer Hüfte
High-Tech, Herzlichkeit und der weite Weg zurück Fünf Wochen sind vergangen, seit ich in der VITREA Ostseeklinik Damp meine neue Hüft-Endoprothese erhalten habe. Wer meinen Blog Artikel „Mein Weg zur neuen Hüfte (TEP) mit 51“ gelesen hat, weiß: Mit 51 Jahren ist das Ziel klar – ich will so schnell wie möglich zurück in ein aktives Leben.…
-

Warum meine neue Hüfte einen Masterplan für Sneaker brauchte
Die Operation ist überstanden, die neue Endoprothese der Hüfte (TEP) sitzt – und nachdem ich mir schon Gedanken über die richtige Rehaklinik oder das Essen im Krankenhaus gemacht habe, hat mich ein ganz anderes Thema gepackt. Man könnte es „Reha-Vorbereitung“ oder „Masterplan für Sneaker“ nennen, aber wer mich kennt, weiß: Es ist nicht nur mein…
-

Mein Weg zur neuen Hüfte (TEP) mit 51
Endlich schmerzfrei: Ein Abschied vom Morbus Perthes und ein technisches Meisterwerk in Damp Es ist ein seltsames Gefühl, wenn ein Schmerz, der einen fast das ganze Leben begleitet hat, plötzlich weg ist. Einfach weg. Aber fangen wir von vorne an, denn meine Reise zu meiner neuen Hüfte (Endoprothese / TEP) begann eigentlich schon, als ich vier…
-

MongoDB 8 Upgrade bei Debian 13 Trixie
Es wurde Zeit, die von mir betreuten MongoDB-Instanzen von Version 7 auf Version 8 zu aktualisieren. Da ein MongoDB 8 Upgrade und die komplett umgebaute apt-Sourcen-Verwaltung bei Debian 13 Trixie eine brisante Gemengelage für ein Upgrade ergeben, habe ich diesmal besonders gründlich gearbeitet. Ich habe eine Schritt-für-Schritt-Anleitung erstellt und diese abgearbeitet. Im folgenden Blogbeitrag halte…
-

Nintendo Switch2
Als Nintendo vor einigen Wochen ankündigte, die neue Nintendo Switch2 zusammen mit einem neuen Mario Kart herauszubringen, konnte ich nicht widerstehen und musste sie gleich bestellen. Wir sind in der Familie Purrucker große Fans von Mario Kart. Mario Kart ist ein tolles Familienspiel, welches allen Altersgruppen spaß macht. Das Spiel ist zwar zeitlos – auch…
-

ALLNET ALL3419: Kosteneffiziente Temperaturüberwachung mit nahtloser Integration in CheckMK
Nach einem Ausfall einer Temperaturüberwachungslösung stand ich vor der Herausforderung, schnell eine zuverlässigen und gleichzeitig kostengünstigen Ersatz zu finden. Die Suche nach einer Alternative führte mich zu verschiedenen Lösungen am Markt, wobei besonders die ALLNET ALL3419 * durch ihr ausgewogenes Preis-Leistungs-Verhältnis hervorstach. Die Anforderungen waren klar definiert: Die neue Lösung sollte nicht nur zuverlässig sein,…
-

Proxmox Backup mit Veeam
In diesem Blog Beitrag schildere ich Euch meine ersten Erfahrungen mit der gerade neu erschienene Feature „Proxmox Backup mit Veeam“. Dieses tolle Feature ist seit dem 28.08.2024 brandneu und mit der Version 12.2 von Veeam erschienen. Da ich selber sehr viele Proxmox Server verantworte, habe ich mir dieses Feature gleich mal näher angesehen. Inhaltsverzeichnis Meine…
-
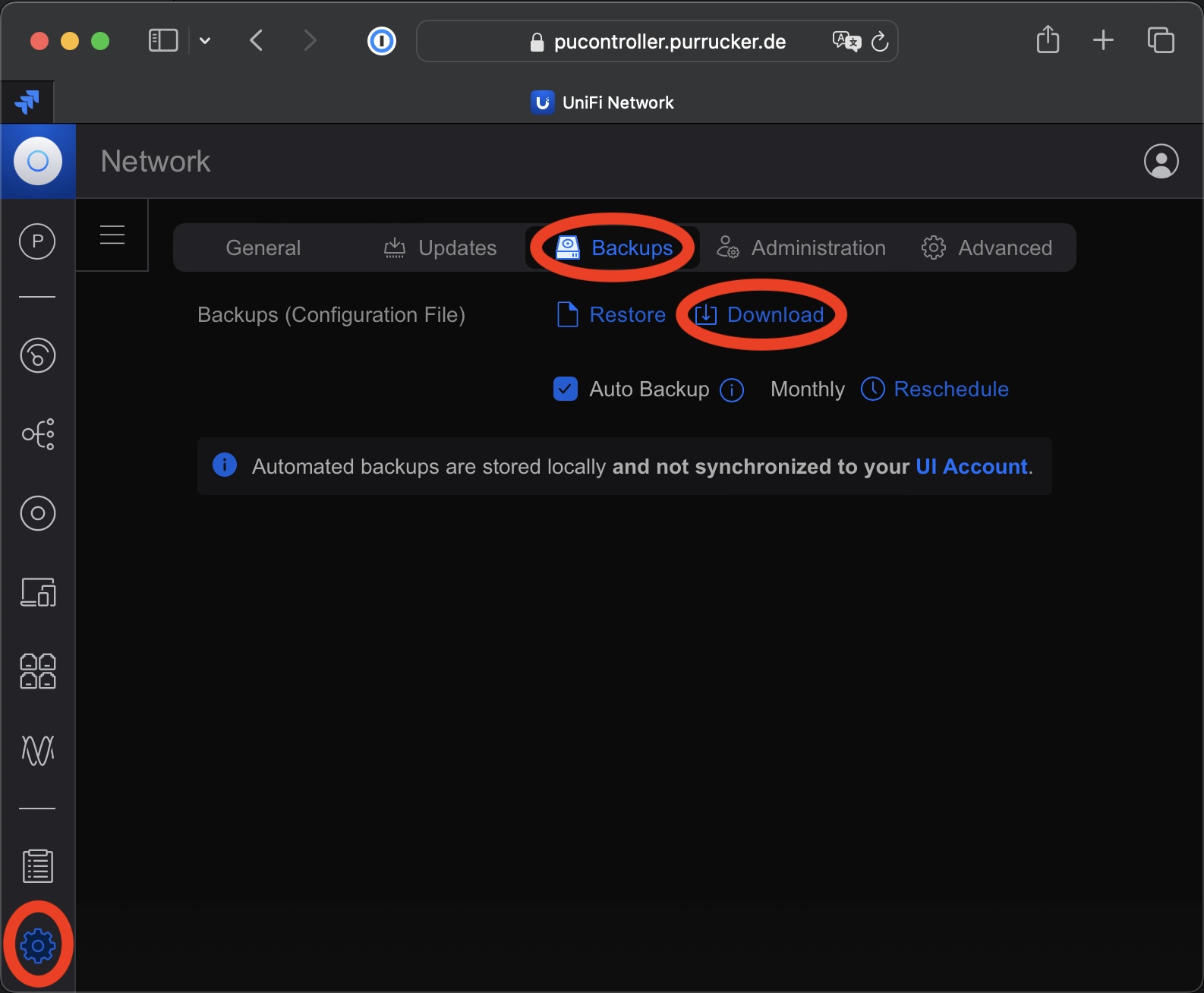
Update einer MongoDB von 3.6 auf 4.4 bei einer UniFi Network Application
Seit Ende letzten Jahres unterstützt die UniFi Network Application von Ubiquiti endlich eine MongoDB die neuer ist als die Version 3.6. Jetzt kann man immerhin die Version 4.4 einsetzen. Somit ist ein Update einer MongoDB von 3.6 auf 4.4 möglich, wenn man eine entsprechende Installation der UniFi Network Application von Ubiquiti betriebt. Diese gestaltete sich…
-
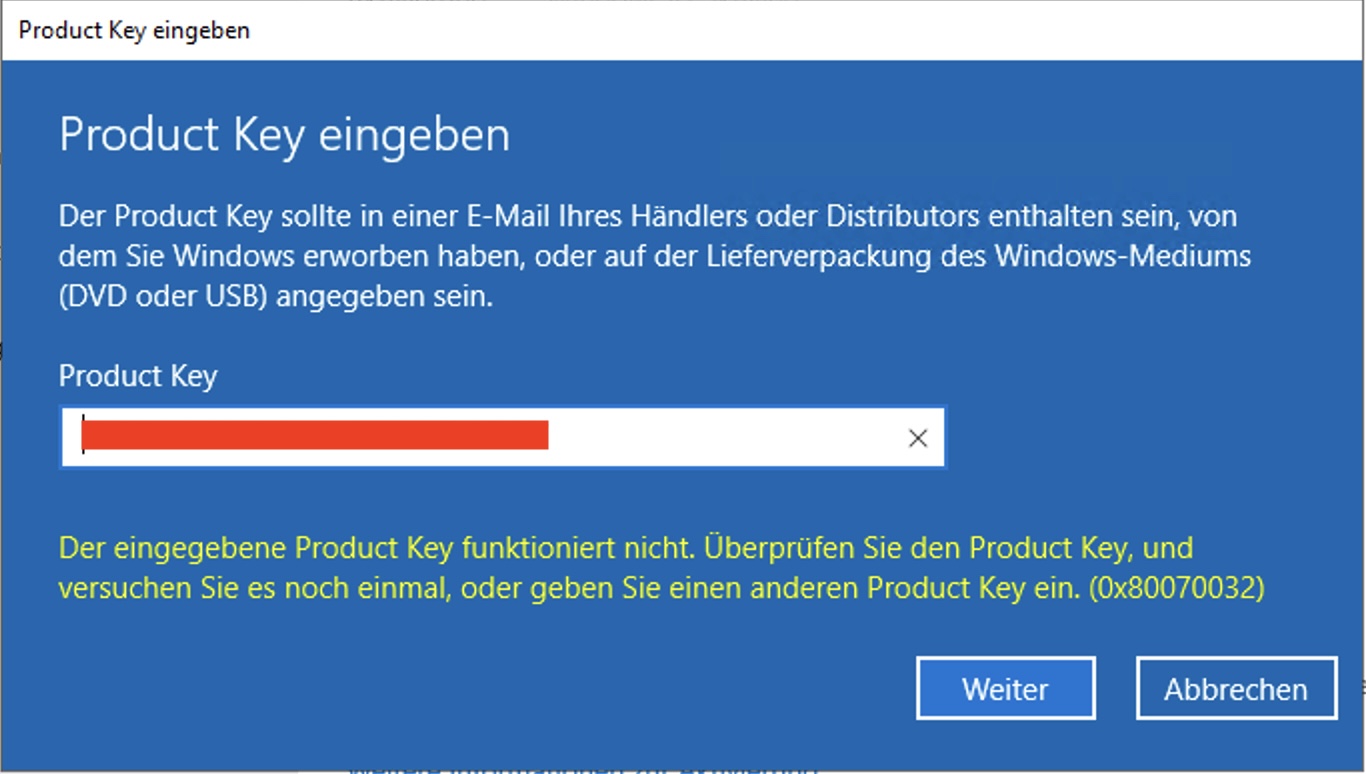
Windows Server aktivieren
Viele Admins werden es kennen. Man möchte einen Windows Server aktivieren und man bekommt die Fehlermeldung (0x80070032): „Der eingegebene Product Key funktioniert nicht“. Was kann man in solchen Fällen machen? Zumindest bei mir hat diese Fehlermeldung bei einem Windows Server 2022 bedeutet, dass die installierte Server Version nicht zum Windows Server aktivieren passt. Das nicht…
-

Microsoft Teams 2.0 ist da
Microsoft hat die von vielen Firmen verwendete Software Microsoft Teams 2.0 freigegeben. Diese kann ab sofort runtergeladen und verwendet werden. In den nächsten Tagen soll die Software schrittweise an die Benutzer ausgerollt werden. Dazu soll in der Titelleiste des Clients eine Nachricht eingeblendet werden, über welche die Benutzer zu der neuen Version wechseln können. In…