Schlagwort: Storage
-

Was bringt das 10 GBit Netzwerk für die DS923+ von Synology?
Ich brauchte mal wieder einen neuen NAS (Network Attached Storage). Und ich habe mich für den brandneuen Synology DS923+ NAS mit 10 GBit Netzwerkkarte entschieden. Es ist der erste kleine NAS dieser Plus-Serie von Synology, in dem eine 10 GB Netzwerkkarte nachgerüstet werden kann. In einem kleinen Erweiterungssteckplatz auf der Rückseite kann dazu eine spezielle…
-
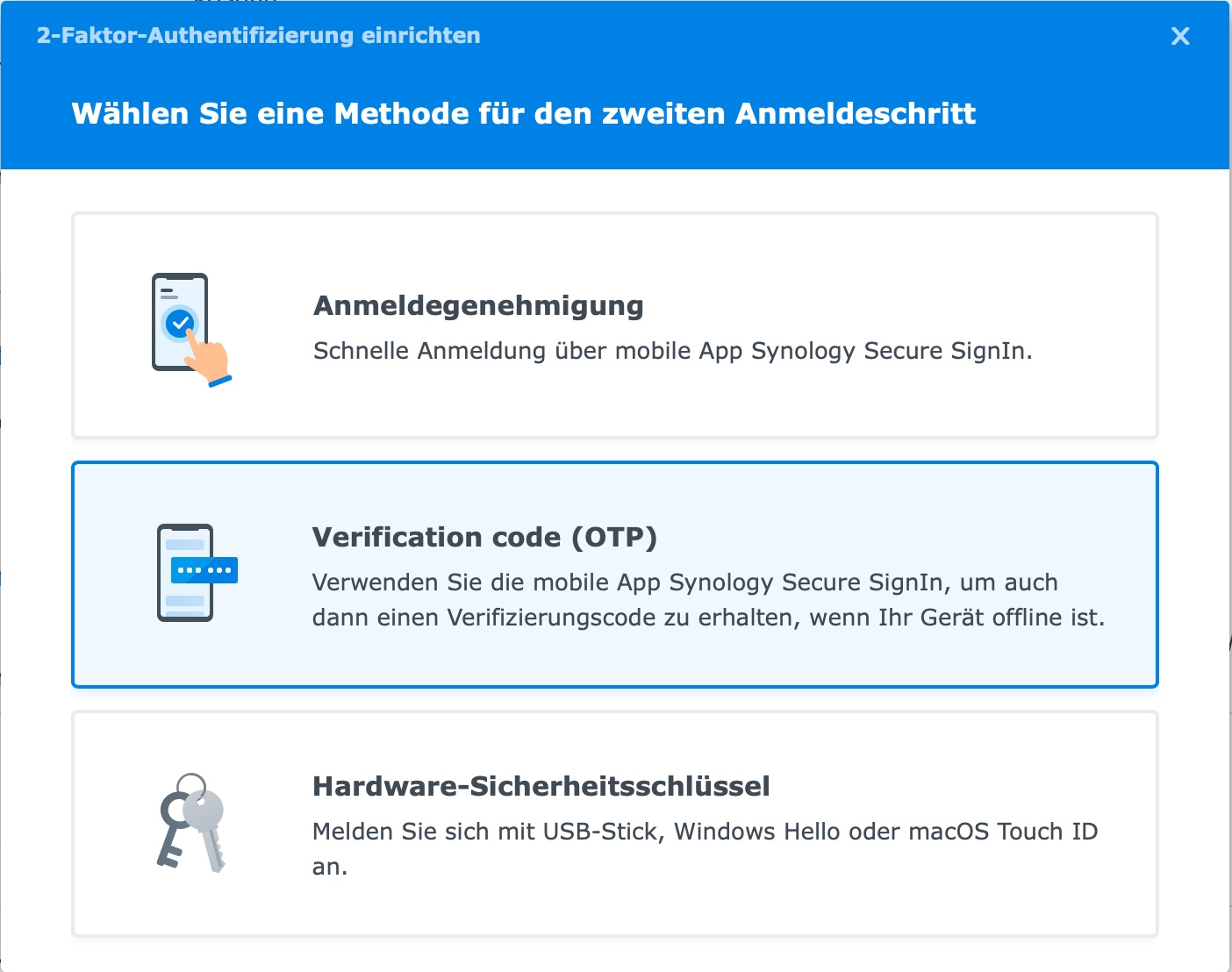
2FA bei einer Synology NAS mit TOTP
Immer wieder hört man von Ransomware (bzw. Krypto-Trojanern), welche Daten auf Servern und Storagesystemen verschlüsseln und Lösegeld erpressen. Umso wichtiger ist es somit seine NAS-Systeme (Network Attached Storage) gegen so etwas abzusichern. Oft wird dazu die sogenannte 2FA (Zwei-Faktor-Authentifizierung) verwendet. Die Zwei-Faktor-Authentifizierung (2FA) ist eine Technik, um die Benutzerkonten vor unberechtigtem Zugriff zu schützen. Sie…
-
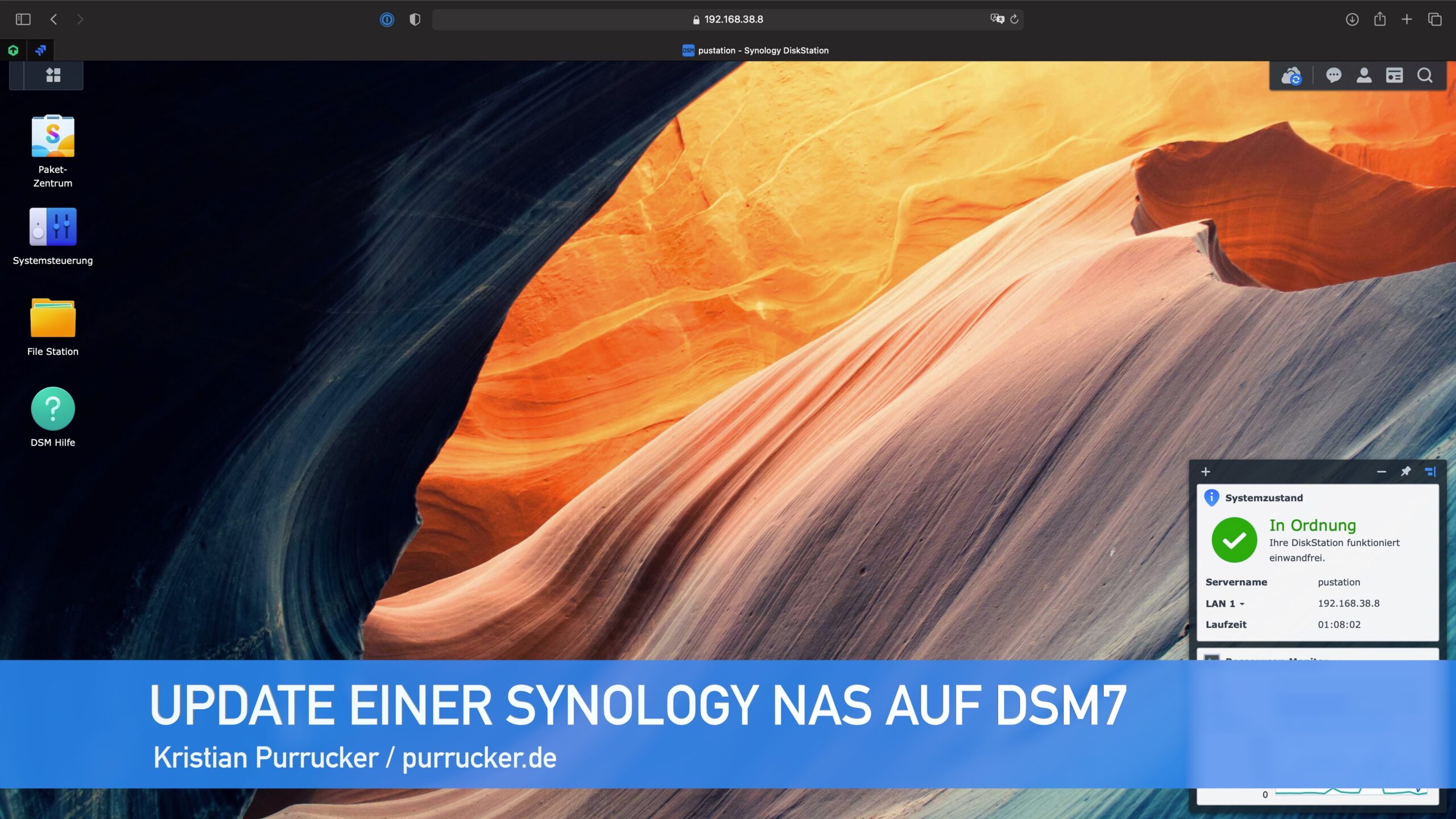
Synology Diskstation Manager 7.0
Endlich ist die bereits sehnsüchtig erwartete Version 7.0 des DSM (DiskStation Manager) von der Firma Synology erschienen. Für diejenigen von Euch die das DSM nicht kennen: Der DSM ist das Betriebsystem für die NAS Systeme der Firma Synology. Es beinhaltet eine Weboberfläche und diverse Anwendungen für die Verwaltung von Daten wie Dateien, Fotos, Videos, usw.…
-

Test einer Synology DS416play mit DSM 6.1
Die taiwanische Firma Synology wurde im Jahr 2000 von den ehemaligen Microsoft Managern Cheen Liao und Philip Wong gegründet und hat sich zum Ziel gesetzt Network Attached Storage-Geräten (kurz NAS) mit umfangreicher Software auf Basis von Linux zu bauen. Dabei nennt Synology die Hardware DS (DiskStation) und die Software DSM (DiskStation Manager). Als ich vor…
-
Überwachung eines LSI SAS2 Controllers (SAS2008) mit Nagios
Der LSI SAS Controller wird durch das Kernel-Modul mpt2sas betrieben. Für das anzeigen des Status wird ein CLI Tool mit dem Namen sas2ircu benötigt. Aktuelle Debian bzw. Ubuntu Pakete sind auf der Webseite http://hwraid.le-vert.net/wiki/DebianPackages#no1 zu finden. Damit man die Ausgabe dieses CLI Tools mit Nagios überwachen kann, benötigt man das Nagios-Plugin check_sas2ircu. Damit das Nagios-Plugin…
-
Überwachung des 3ware Controllers SAS9750-8i mit Nagios
Um den Status eines RAID bei einem 3ware Controller abzufragen, gibt es ein CLI Tool mit dem Namen tw_cli. Jonas Genannt war so nett und hat dazu ein paar Debian-Pakete gebaut, die auch unter Ubuntu laufen. Diese findet man auf der Webseite http://jonas.genannt.name/ (Update: Leider gibt es diese Webseite nicht mehr und ich habe den…
-
AHCI nachträglich bei Windows 7 oder Vista aktivieren
Als ich Vorgestern ein Image eines Windows 7 Computers auf neue Hardware übertrug stellte ich überrascht fest, dass der Bootvorgang mit einem Bluescreen durch einen stop 0x0000007B error beendet wurde. Dieser Fehler kommt, wenn Windows auf seine Bootfestplatte nicht zugreifen kann. Wenn er nach einem Hardwarewechsel auftaucht, hat man meistens einen falschen oder nicht vorhandenen…
-
Überprüfen der Festplattenauslastung bei Linux
Bei Servern will ab und zu die Festplattenauslastung überprüfen. Gerade wenn auf einem Server mehrere virtuellen Gäste laufen, ist es sehr interessant zu erfahren wie ausgelastet ein Controller bzw. die Festplatten an diesem sind. Um die Auslastung zu überprüfen eignet sich unter Linux meiner Meinung nach sehr gut das Programm iostat. Dies ist unter Debian/Ubuntu…
-
Erweitern eines Datenträgers unter Windows Server 2003, Windows XP und Windows 2000
Im Gegensatz zu Windows 2008 und Windows 2008R2 ist es bei älteren Windows Versionen nicht möglich Partitionen über die Datenträgerverwaltung zu erweitern. Dies geschieht hier über das Kommandozeilentool diskpart.exe. Wenn man in einer Eingabeaufforderung diskpart.exe eingibt, erscheint eine Shell. In dieser kann man sich mit dem Befehl list volume eine Liste der Datenträger anzeigen lassen.…
-
Linux: Austausch einer defekten Festplatte im Software-RAID
Der Status des Software RAID (Redundant Array of Independent Disks) wird bei Linux in der Datei /proc/mdstat festgehalten. Man kann sich den Status eines RAID also mit folgenden Befehl anzeigen lassen: cat /proc/mdstat Wenn z.B. die Festplatte /dev/sdb defekt ist, könnte die Ausgabe von wie folgt aussehen: Personalities : [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]…