
-
Wie wir einen USA Urlaub planen

Wir wurden schon mehrfach gefragt, wie wir auf die Ideen für unsere Amerikareisen kommen. Deshalb schildere ich diesem Blogartikel am Beispiel des diesjährigen USA Roadtrips in den Rocky Mountains, wie wir unseren USA Urlaub planen im Detail. Die meisten unserer Reiseplanungen starten mit langwierigen Diskussionen an unserem Küchentisch, die sich oft über mehrere Tage hinziehen.…
-
Update einer MongoDB von 3.6 auf 4.4 bei einer UniFi Network Application
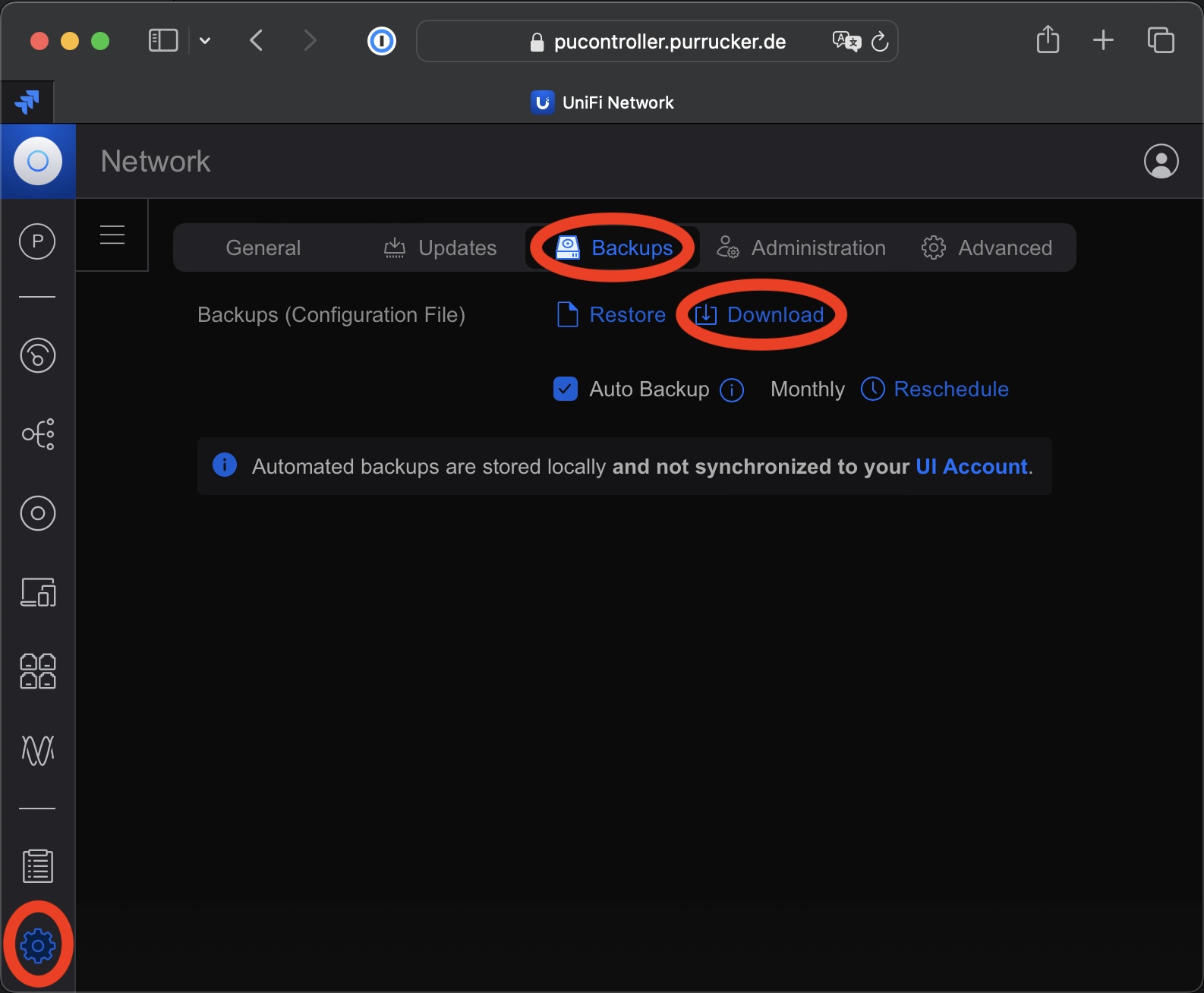
Seit Ende letzten Jahres unterstützt die UniFi Network Application von Ubiquiti endlich eine MongoDB die neuer ist als die Version 3.6. Jetzt kann man immerhin die Version 4.4 einsetzen. Somit ist ein Update einer MongoDB von 3.6 auf 4.4 möglich, wenn man eine entsprechende Installation der UniFi Network Application von Ubiquiti betriebt. Diese gestaltete sich…
-
Kurzurlaub in England

Da Clara zur Zeit in Oxford mit ihrer Doktorarbeit beschäftigt ist und wir sie sehr vermissen, beschliessen wir kurzerhand einen Kurzurlaub in England zu machen und sie an ihrem Geburtstag zu besuchen. Die Anreise zum Kurzurlaub in England Die 1.150 km lange Anfahrt dauert 16 Stunden. Zunächst geht es 10 Stunden lang mit dem Auto…
-
Windows Server aktivieren
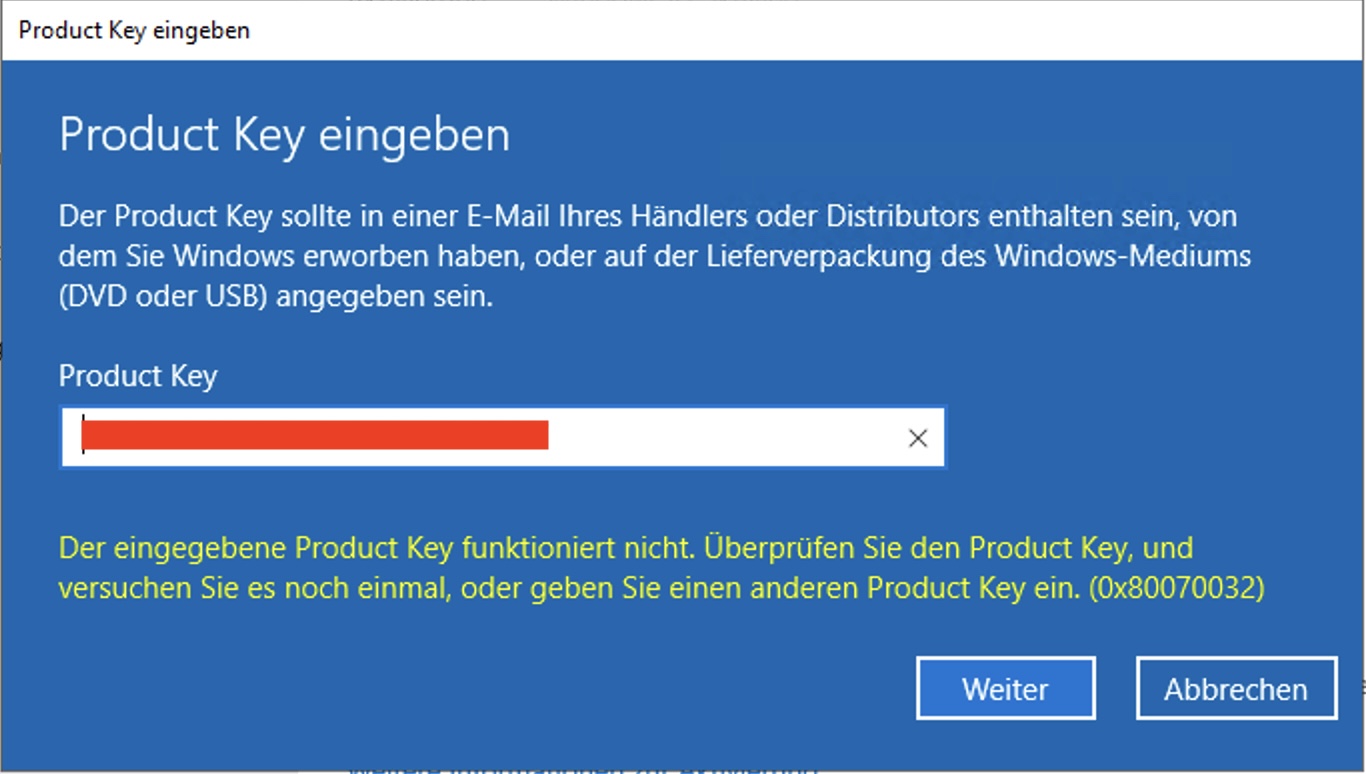
Viele Admins werden es kennen. Man möchte einen Windows Server aktivieren und man bekommt die Fehlermeldung (0x80070032): „Der eingegebene Product Key funktioniert nicht“. Was kann man in solchen Fällen machen? Zumindest bei mir hat diese Fehlermeldung bei einem Windows Server 2022 bedeutet, dass die installierte Server Version nicht zum Windows Server aktivieren passt. Das nicht…
-
Alpencross mit dem Gravelbike | Teil 2

Nach der Überquerung des Alpenhauptkamm und der Ankunft in Grosio in Italien ist der Alpencross mit dem Gravelbike eigentlich schon perfekt. Traditionell enden der Alpencross jedoch immer am Gardasee. Deshalb wollen auch wir von Grosio noch quer rüber nach Torbole am Gardasee fahren. Wer etwas über den ersten Teil unseres Alpencross mit dem Gravelbike lesen…
-
Microsoft Teams 2.0 ist da

Microsoft hat die von vielen Firmen verwendete Software Microsoft Teams 2.0 freigegeben. Diese kann ab sofort runtergeladen und verwendet werden. In den nächsten Tagen soll die Software schrittweise an die Benutzer ausgerollt werden. Dazu soll in der Titelleiste des Clients eine Nachricht eingeblendet werden, über welche die Benutzer zu der neuen Version wechseln können. In…
-
Alpencross mit dem Gravelbike | Teil 1

Während Cora es in diesem Sommer etwas ruhiger angehen lässt und unseren nächsten großen Urlaub in den USA plant, brauche ich auch in diesem Sommer ein richtiges Abenteuer. Deshalb plane ich einen Alpencross mit dem Gravelbike. Ich wollte schon immer mal nur mit reiner Muskelkraft auf Feldwegen und Singletrails über die Alpen. Cora rät mir…
-
Port Forwarding mit ssh
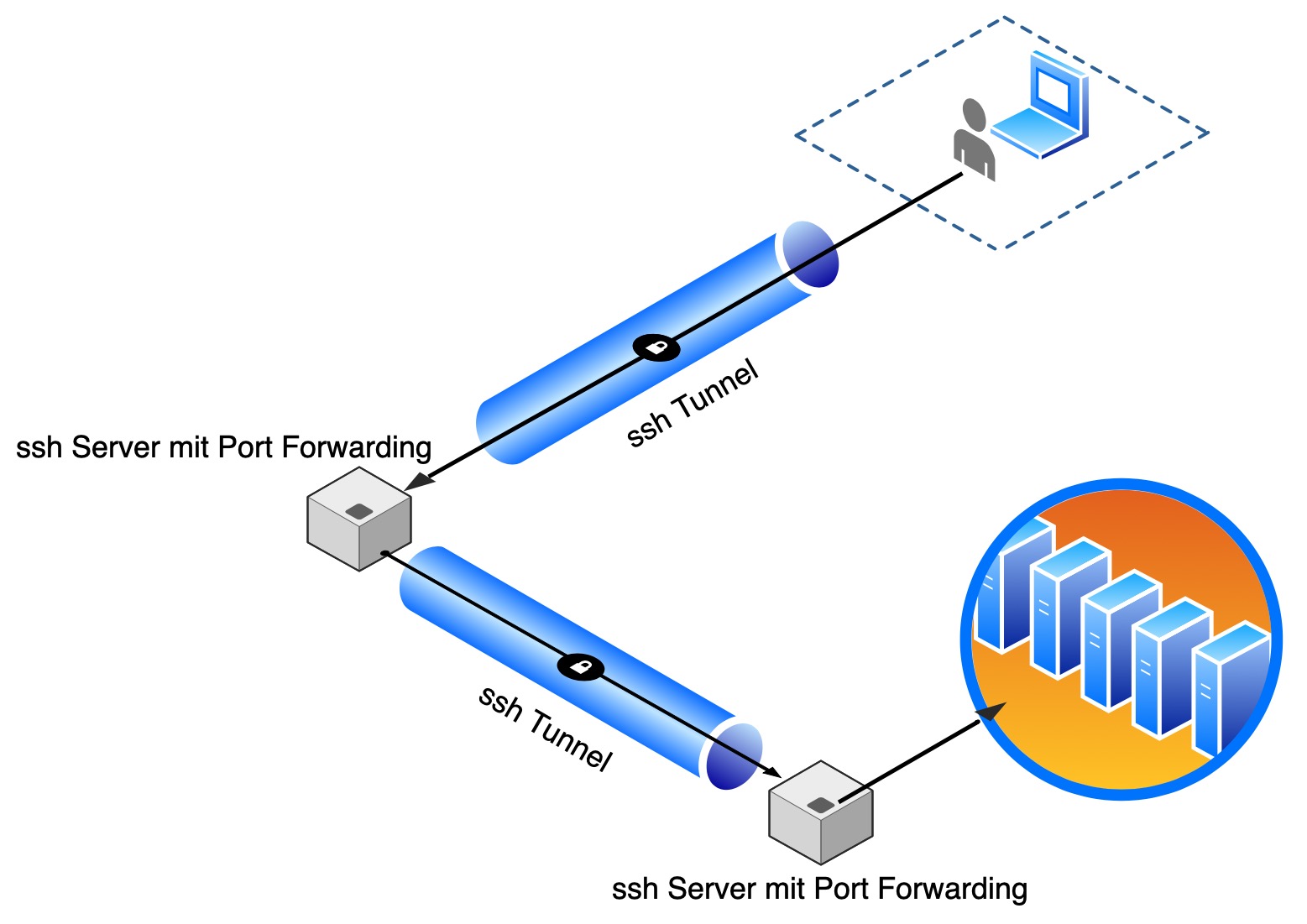
Port Forwarding mit OpenSSH ist eine sichere und flexible Methode, um auf entfernte Dienste zuzugreifen und Datenverkehr zwischen dem lokalen Rechner und einem entfernten Server sicher und verschlüsselt zu transportieren. Dies ist besonders nützlich für Systemadministratoren, Entwickler und alle, die oft sichere Verbindungen zu entfernten Servern herstellen müssen. Einfacher als das Port Forwarding mit ssh…
-
Im wilden Westen der USA | Teil 10: San Diego und Oceanside am Pazifik

In diesem Teil starten wir in unserem Hotel in Palm Springs und fahren nach San Diego und Oceanside. Im kleinen Badeörtchen Oceanside schauen wir uns den legendären Strand und den mit 592 Meter längsten, hölzerner Pier der amerikanischen Westküste an. In San Diego testen wir die mexikanische Küche und besichtigen den Flugzeugträger MSS Midway. Wie…
-
ssh als SOCKS Proxy
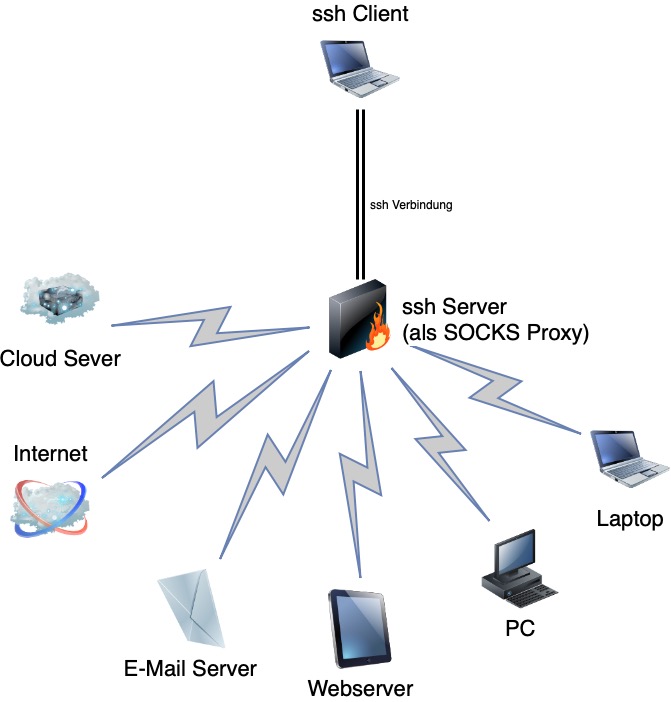
Durch die Möglichkeit ssh als SOCKS Proxy zu verwenden ist es möglich Verbindungen durch eine ssh-Verbindung zu Tunneln. Dadurch kann man auf Geräte zugreifen, die sich in Netzen befinden, auf welche kein direkter Zugriff besteht. Es reicht aus sich mit einem Gerät per ssh zu verbinden, welches Zugriff auf das gewünschte Zielsystem hat. Anschließen wird…
Mikroblog bei Mastodon
- Loading Mastodon feed…