Schlagwort: Ubuntu
-

Kritische Sicherheitslücke in ClamAV (CVE-2023-20032)
Es gibt eine kritische Sicherheitslücke in ClamAV mit der CVE Nummer CVE-2023-20032 und alle Nutzer dieser Software sollten dringend auf eine abgesicherte Version aktualisieren. Da ClamAV in sehr vielen Softwareprodukten eingebaut ist, ist eine große Anzahl von Systemen betroffen. Bedauerlicher Weise gibt es aktuell noch nicht für alle Systeme entsprechende Updates. Da sehr viele oder…
-
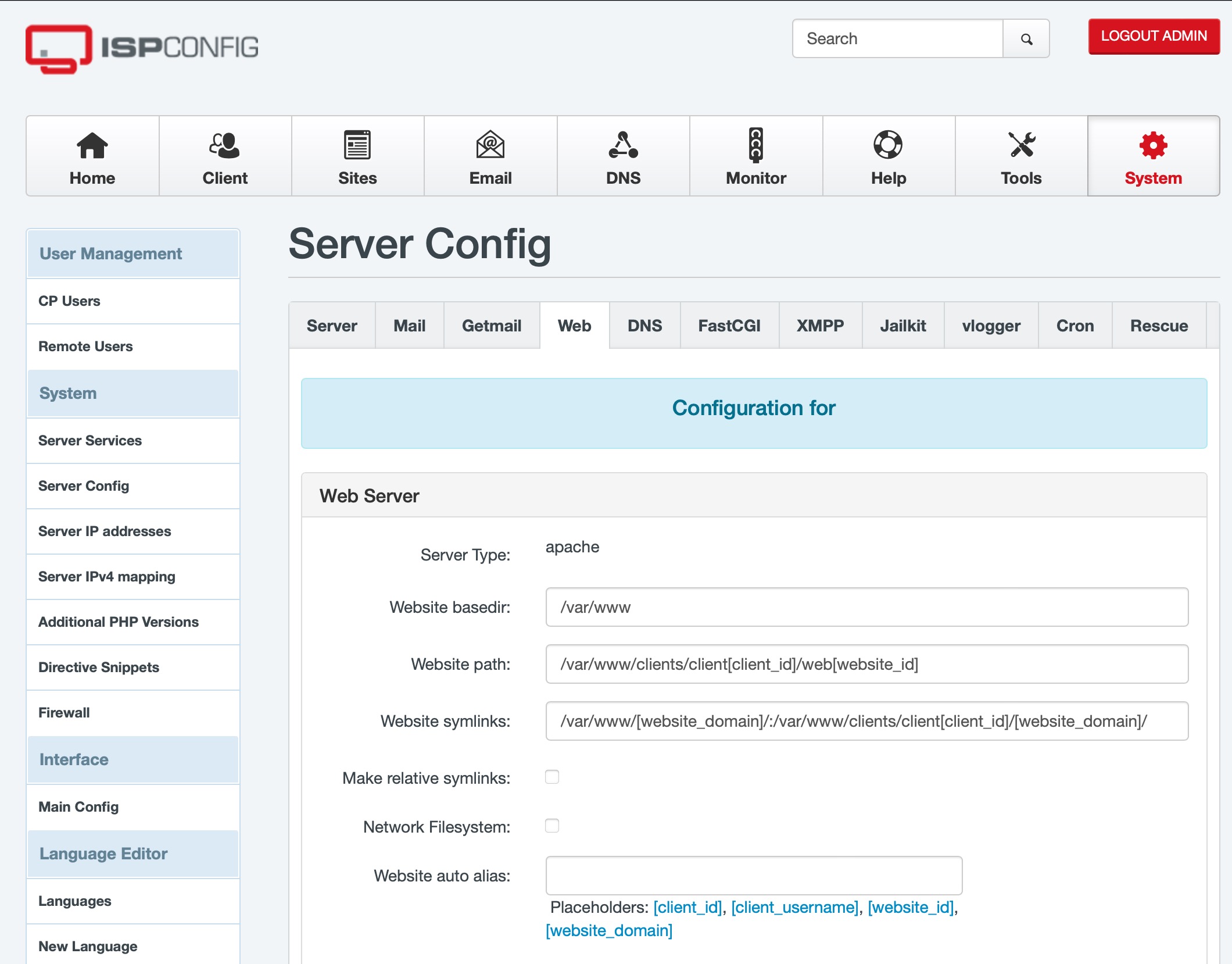
Update eines ISPConfig Perfect Server von Ubuntu 20.04 auf Ubuntu 22.04
Endlich ist das Update eines ISPConfig von Ubuntu 20.04 auf Ubuntu 22.04 möglich! Lange hat es gedauert, aber ab der am 21. November 2022 veröffentlichten Version 3.2.9 unterstützt ISPConfig endlich Ubuntu 22.04. Zumindest, wen man mailman nicht verwendet, welches bei Ubuntu 22.04 nur noch in der von ISPConfig noch nicht unterstützten Version 3 enthalten ist.…
-
Installation einer neueren PHP-Version auf einem älteren Ubuntu
Es kommt gerade bei den LTS-Versionen von Ubuntu immer häufiger vor, dass eine Software zwingend eine neuere PHP-Version voraussetzt, als auf einem Server mit einem Ubuntu Betriebssystem gerade installiert ist. Wie kann ein solche Herausforderung lösen? Eine Möglichkeit diese Anforderung zu erfüllen ist ein Upgrade des Ubuntu auf ein neues Release. Oft möchte man dies…
-
Ubiquiti Unifi: Releaseupgrade eines Ubuntu 16.04 auf 18.04 mit einer Mongodb
Mehrere Installationen der Software Unifi von Ubiquiti liefen bei mir noch auf einem Ubuntu 16.04 LTS. Da die kostenlosen Sicherheitsupdates für dieses Ubuntu nur noch ein halbes Jahr erscheinen, war es Zeit für ein Releaseupgrade auf Ubuntu 18.04. Gesagt, getan… Nach einem Backup eines der Controller führte ich kurzerhand ein Releaseupgrade durch. Das eigentliche Releaseupgrade…
-
Let’s Encrypt Zertifikate für Postfix und Dovecot einrichten
In letzter Zeit wird die Verwendung der kostenlosen Zertifikate von Let’s Encrypt immer beliebter. Deshalb ist es naheliegend, diese auch für Verschlüsselung der Mails bei Postfix zu verwenden. Im folgenden sind die wenigen Schritte für die Einrichtung erklärt, die bei einem Ubuntu 18.04 notwendig sind. Installation Let’s Encrypt können mit dem certbot erzeugt werden. Die…
-
IPv6 auf einem Ubuntu 18.04 Server deaktivieren
Selbst in der heutigen Zeit bereiten Server die sowohl eine IPv4 als auch eine IPv6 Adresse haben manchmal Probleme. Deshalb kann es nützlich sein, wenn man die IPv6 Adressen eines Server komplett deaktiviert. Bei Ubuntu 18.04 LTS geht das wie folgt. Man legt die Datei /etc/sysctl.d/01-disable-ipv6.conf mit dem folgenden Inhalt an und startet den Server hinterher…
-
Erster Test von Ubuntu 18.04 LTS
Ich habe mir gerade den RC (Release Candidate) von Ubuntu 18.04 LTS angesehen. Das LTS steht bei Ubuntu für Long Term Support und bedeutet, dass es 5 Jahre lang Sicherheitsupdates für die Release von Ubuntu geben wird. Die LTS Version erscheint aktuell alle zwei Jahre und ist durch den langen Zeitraum mit Sicherheitsupdates besonders für…
-
Bei einem Linux unter VMware im laufenden Betrieb eine Festplatte einbinden
Oft ergibt sich die Notwendigkeit auf einem Server mit Linux im laufenden Betrieb eine neue Festplatte anzuschließen. Z.B. wenn der Server virtuell unter VMware läuft und man diesem eine neue Festplatte zuordnet hat und diese ohne Neustart des Servers einbinden möchte. Um dies bei einem Server mit Linux zu machen benötigt man als erstes die…
-
VMware-Tools oder lieber open-vm-tools verwenden?
Die VMware-Tools sind Programme und Treiber, mit denen die Gastbetriebssysteme in einer virtuellen Maschine unter VMware zusätzliche Funktionalitäten erhalten. Durch diese wird die Arbeit erleichtert und die Leistung verbessert. Seit dem Jahr 2007 hat VMware weite Teile der VMware Tools als Open Source Software unter dem Namen open-vm-tools (Open Virtual Machine Tools) freigegeben. Bei aktuellen Linux…
-
Vielen Dateien eine andere Dateiendung geben
Ab und zu hat man bei der Administration die Aufgabenstellung vielen Datei eine andere Dateiendung zu geben. Hier eine kleine Programmzeile, mit der man diese Aufgabe sehr erleichtern kann. Mit dieser kann man unter Linux oder MacOSX an alle Dateien in einem Verzeichnis die Dateiendung „.pdf“ anhängen.